I will talk about how I’ve gone about this assignment. If there is anything here that is vague/confusing, please drop a comment so I can fix it up.
Preprocessing
In terms of loading in the audio, I used SciPy’s io.wavfile.read method,
which returns a NumPy array of integers (and a sample rate). In my case, the
sample rate was 16,000, so the length of the array was approximately 16,000*60*60*3 (i.e., 3 hours of audio). The only pre-processing I did was scale the array so that its values lied between 0 and 1, using 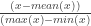
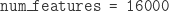

Formulation
Formally, we have the entire audio sequence 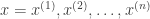
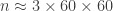
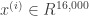
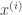
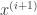

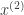
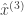



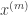

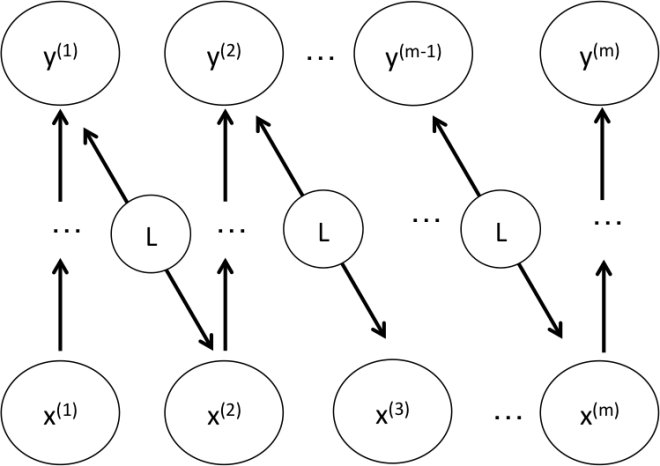
The network architecture I used was an LSTM consisting of 3 layers of 600 units (the architecture definition file is here). I have a gut feeling that this architecture might be overkill (it has 55 million parameters!), and it’s probably possible to reproduce my result with a much more lightweight network.
Software
For this project I used Lasagne, which is a lightweight neural network library for Theano. I can’t compare this with any other framework (such as Keras or Blocks), but Lasagne is really easy to use and it tries not to abstract Theano away from the user, which is comforting for me. The documentation is really nice too! There is even some example RNN code here to get you started (it certainly helped me). An example of an LSTM in Lasagne for text generation can be found here as well, and hopefully opens your mind up to the possibility of doing all sorts of cool things with LSTMs. 🙂
Results
I have plotted some learning curves for this model (the raw output is here):
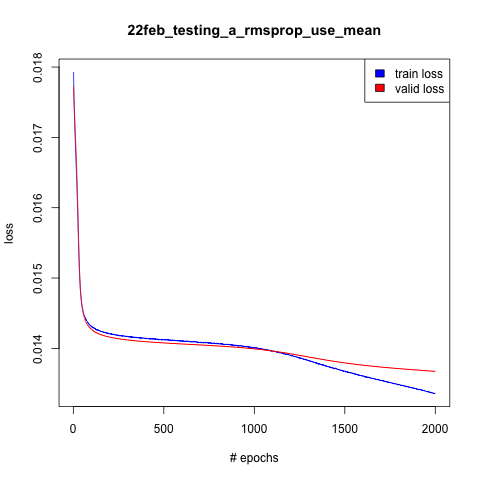
You can see that at around 1000 epochs is when the network starts to overfit the data (since the training curve dives down), so that would have been an appropriate time to terminate model training. It is good to see that from 0 to 1000 epochs the training and validation curves are in close proximity — if the training curve was significantly below the validation curve then I would be concerned.
Each epoch takes about ~3.7 seconds, and overall the model took 125 minutes to train on a Tesla K40 GPU.
My next step is to train another LSTM but with less units in each layer — I’d really like to know if my architecture is a bit overkill.
Notes
** Originally this was 
*** Yoshua made an interesting point in class, in that by letting 
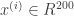
Other thoughts:
* Admittedly, I realised that the whole time I was training these LSTMs that the nonlinearity I was using on the output was 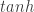
* It is interesting how I am not able to generate audio past 50 seconds. It seems to be that there is some kind of “input drift” (since I am feeding the LSTM’s generated output into its input repeatedly), and when the input has “drifted far enough”, the LSTM doesn’t know how to recover from it and generates nonsense/white noise. This sounds like a teacher forcing / generalisation issue: the inputs that the RNN gets at training time are the actual inputs, so there is a lot of hand-holding going on. In test time (i.e., when we generate new sequences), the outputs are being fed back as inputs, and if the network has not generalised well enough then we run into issues. It seems like the most obvious way to combat this is to, during training, let some of these actual inputs 
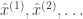

On your last point: there was a paper at this past NIPS by Samy Bengio and the guys at Google, called “Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks” (http://arxiv.org/pdf/1506.03099v3.pdf), which should be flose to what you are looking for.
LikeLike
Beautiful! A natural concern is the following: is this network overfitting? Are you monitoring the validation set NLL during training? Please show the training and validation NLL curves vs epoch. How long does it take to train to this point? (and per epoch?).
LikeLike
Hi Yoshua,
I will update the blog post shortly. I should have definitely included some learning curves — thanks for reminding me!
LikeLike
Just a statistical somewhat-minor point: when you calculate and subtract the mean from your train/test/validation sets, I think this mean should be _of the training set_ … otherwise you’re technically cheating on the test/validation?
LikeLike
oops, I meant cheating information from the test/validation into the training (i.e. you shouldn’t know about those when you train)
LikeLike
Yes you could also do it that way too but it’s a really minor detail — validation/test set contamination becomes an issue when you do things like use valid/test set class labels.
LikeLike