Melvin Wong managed to defeat the ticking sound issue, good job! https://melvinwong6266.wordpress.com/2016/04/19/day-16-finale-part-2-getting-things-done/
I was going to do this technique myself but I don’t seem to see how it can be done for the way I generate my sequences. (Melvin, if you’re reading this, correct me in the comments if I have made a mistake.)
Melvin appears to generate his sequences using a sort of sliding window approach. So let’s say you have some seed sequence [x1, x2, x3, x4] (this will also be our initial “generated sequence”). You feed this seed sequence to your RNN and get an output [x5]. Now, let’s concatenate [x5] to the generated sequence:
[x1,x2,x3,x4,x5]
Now, let’s remove [x1]:
[x2,x3,x4,x5]
Now, let’s feed [x2,x3,x4,x5] to the RNN and get [x6]:
[x2,x3,x4,x5,x6]
Now, remove [x2]:
[x3,x4,x5,x6]
In this situation, it would make sense that you would get ticking, because you’re feeding [x2,x3,x4,x5] into the RNN and it has no knowledge of [x1]. Likewise, when you feed [x3,x4,x5,x6] into the RNN, it has no knowledge of [x1] or [x2].
I do this technique to generate sequence: given an initial sequence [x1, x2, x3, x4], feed it into the RNN to get [x5]. Now concatenate. Now feed [x1,x2,x3,x4,x5] into the RNN to get [x6]. Now concatenate. Now feed [x1,x2,x3,x4,x5,x6], etc… I always feed the RNN a much longer sequence in each iteration. I can perhaps see this technique as being a perhaps not so good idea, because I train the RNN on fixed length sequences (and at test time it’s getting sequence lengths it’s never seen), but it seems like Melvin’s technique won’t work in my case, because the RNN always gets the “full history” of the generated sequence.
 , which is 1/4th of a second since the sampling rate is 16,000. This means that each mini-batch is
, which is 1/4th of a second since the sampling rate is 16,000. This means that each mini-batch is  seconds of audio.
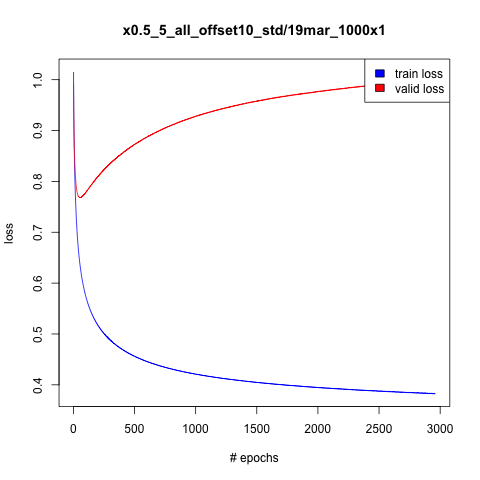
seconds of audio. ). I did get a slight reduction in validation set loss but it isn’t all that much. I also tried adding some gaussian noise to the input and didn’t get anything (
). I did get a slight reduction in validation set loss but it isn’t all that much. I also tried adding some gaussian noise to the input and didn’t get anything (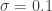 ). Perhaps it is worth to crank up the dropout probability a bit and see what happens.
). Perhaps it is worth to crank up the dropout probability a bit and see what happens.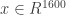 . The audio I generate seems to sound more homogenous, which is not a good thing. This is an interesting result because this experiment uses the same sequence length in seconds as the previous experiment. For example, the previous experiment used
. The audio I generate seems to sound more homogenous, which is not a good thing. This is an interesting result because this experiment uses the same sequence length in seconds as the previous experiment. For example, the previous experiment used  of size 2000 (1/8th of a second), with a sequence length of 40, such that 2000*80 / 16000 = 10 seconds, and this experiment we have a sequence length of 100, such that 1600*100 / 16000 = 10 seconds. As of now I am not sure why this is the case.
of size 2000 (1/8th of a second), with a sequence length of 40, such that 2000*80 / 16000 = 10 seconds, and this experiment we have a sequence length of 100, such that 1600*100 / 16000 = 10 seconds. As of now I am not sure why this is the case.



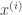 and the successive time chunk
and the successive time chunk 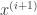 .
.
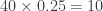 seconds long. What if we instead make
seconds long. What if we instead make 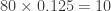 seconds. Having a “longer” memory sounds essential to generate audio that is more diverse.
seconds. Having a “longer” memory sounds essential to generate audio that is more diverse.


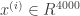 instead, i.e., 1/4 of a second. I feel as if making
instead, i.e., 1/4 of a second. I feel as if making 